

【Poseidon】Story上に構築されたフィジカルAIのためのデータ収集プロトコル / RoboFi市場のフラッグシップアプリ / 音声データ収集キャンペーン開始 / @psdnai
Storyがオフィシャルに支援する面白そうなプロジェクトです。


おはようございます。
web3リサーチャーのmitsuiです。
今日は「Poseidon」についてリサーチしました。
🤖Poseidonとは?
⚙️技術的な仕組み
🚩変遷と展望
💬RoboFi市場のフラッグシップアプリ
🧵TL;DR
PoseidonはStory Protocol上のデータ基盤で、枯渇する汎用Webデータに代わりAIに実世界のロングテール/エッジケースデータを供給することを狙う。
フィジカル/エンボディドAI向けにFPV動画・多方言音声・夜間/悪天候走行など、権利クリアな高品質データを分散収集。
StoryのIPグラフで親子IPを追跡し、オンチェーンライセンスと自動ロイヤリティ分配で貢献者にインセンティブを付与。
2025/9/3にβ版アプリ公開(まず音声収集、メール/Googleで自動ウォレット・報酬ポイント付与)。a16z支援の新章として今後拡大予定。
🤖Poseidonとは?
「Poseidon」は、IP特化のブロックチェーンであるStory Protocol上に構築されたデータ基盤プロジェクトです。
その詳細を説明するためにも、まず現代のAI開発が直面している根源的な課題である「データの枯渇」について説明します。
第一世代のAI基盤モデルは、インターネット上に公開されている膨大なテキストや画像データを「燃料」として驚異的な進化を遂げました。これらの簡単に手に入るデータはAI開発者によってほぼ採り尽くされたと言っても過言ではありません。
この現状は、AI開発における課題を浮き彫りにしています。同じ種類のデータを大量に追加投入しても、モデル性能の向上は次第に鈍化していくため、次世代AIの飛躍的進化は、もはやモデルの規模(パラメータ数)の増大ではなく、より高品質で多様性に富んだ、これまでアクセスできなかった新しい種類のデータにかかっています。
この問題に関して、a16z Cryptoの創設者であるChris Dixon氏が「AI基盤モデルは、最もアクセスしやすいトレーニングデータをすでに使い果たしてしまった」と指摘しており、Poseidonはまさにこの問題を解決しようとしています。
もう少し説明は続きます。
AI領域で次なる革新領域として注目されているのは、「フィジカルAI」または「エンボディドAI」と呼ばれる、スクリーンの中の世界を超えて物理世界で活動するシステムです。
これには、人型ロボット、自動運転車、ウェアラブルデバイス、空間コンピューティングなどが含まれますが、これらのシステムにとって、インターネットからスクレイピングされたデータは不十分です。なぜなら、物理世界での活動には、マルチモーダルで、文脈依存性が高く、予測不能な「エッジケース」を豊富に含んだデータが不可欠だからです。
例えば、ロボットの操作タスクを学習させるための主観視点(FPV)ビデオ、多様な方言や騒音環境に対応するための音声データ、夜間や悪天候下での走行データといった、いわゆる「ロングテールデータ」と呼ばれるデータが必要となってきます。
Poseidonの共同創設者であり、Story Protocolの最高AI責任者でもあるSandeep Chinchali氏が、自身の研究経験から「エッジケースを捉えた1%の映像が、モデル性能の最も大きな向上をもたらした」と述べているように、この種の希少で非構造化され、かつ法的に収集が困難な実世界データこそが、次世代AIの性能を決定づける最も価値ある資産と言えます。
Poseidonはこの自動運転やロボットなど物理世界で動作するAIに必要なニッチで多様な「ロングテール」データを対象とし、データ提供者(撮影者やラベラーなど)からAIモデル開発者まで、関与するすべての人々に対して貢献度に応じたインセンティブと法的保護を与えることを目指しています。
◼️β版リリース
そんなPoseidonですが、2025年9月3日にデータ提供者が参加できるPoseidonアプリが公開され、誰でもAIモデルの訓練に役立つデータを提供して報酬を獲得できるようになりました。
いずれはあらゆるデータ収集を目指しているとのことですが、初期アプリでは音声収集に特化しています。
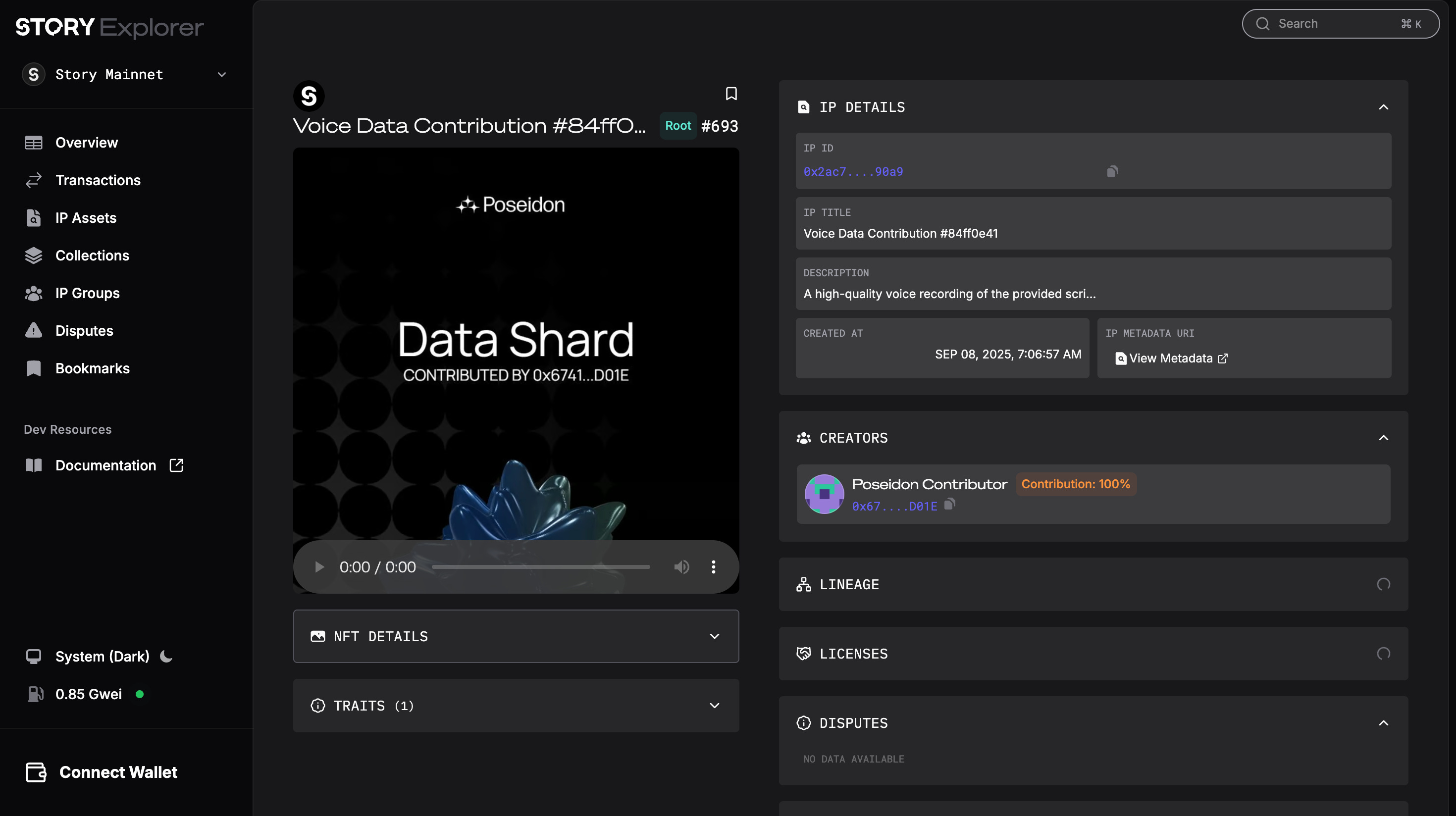
Poseidonアプリにアクセスすると、以下のような画面になります。この中で自身の言語を選択します。日本語もちゃんと存在します。ちなみにウォレットコネクトの必要はなく、メールアドレスまたはGoogleログインで自動でウォレットが生成されます。

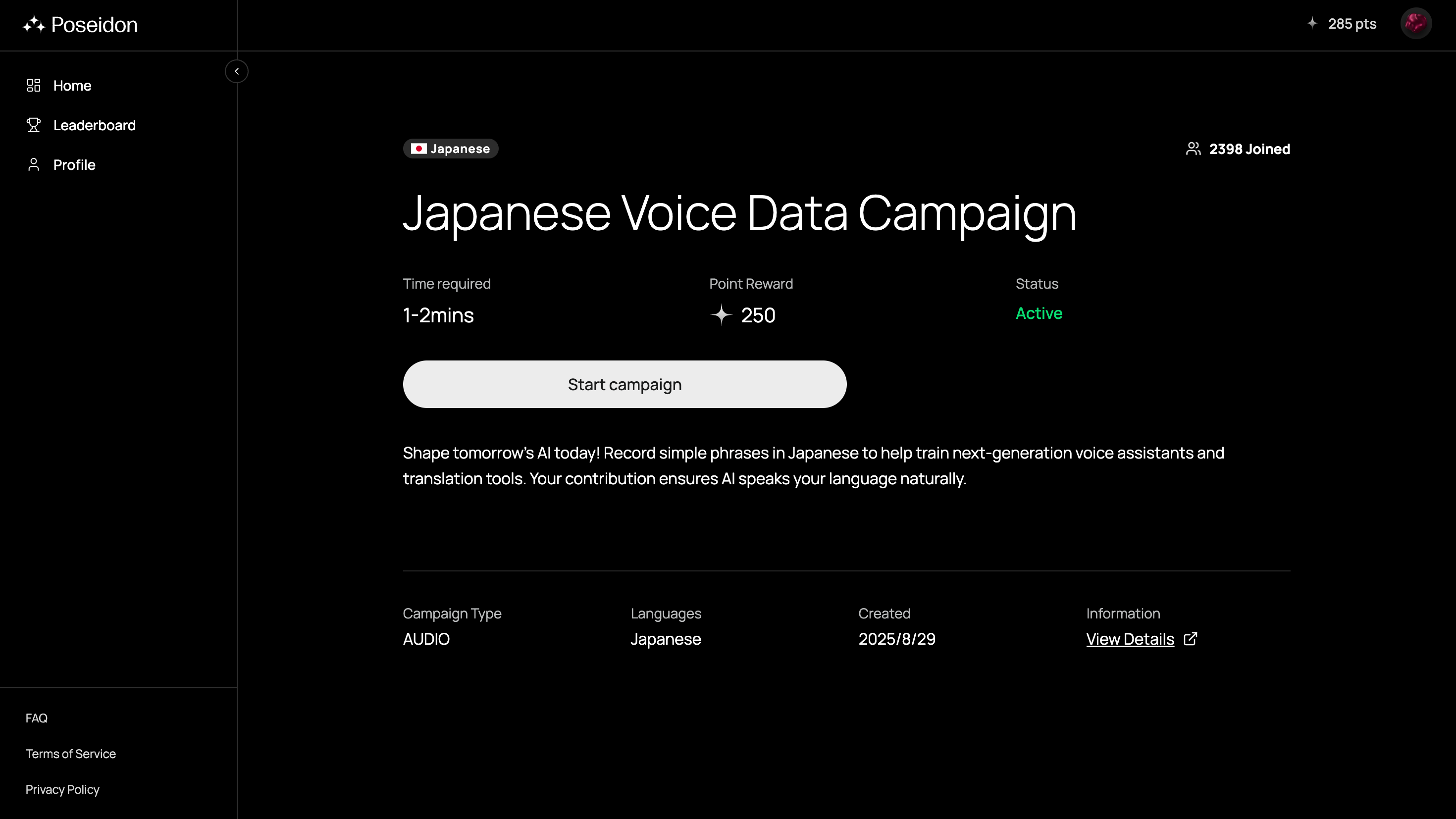
日本語のキャンペーンをクリックすると以下のような画面となり、キャンペーンをスタートします。
すると、以下のように1分程度で読み上げられる原稿が表示されるのでこれを収録します。
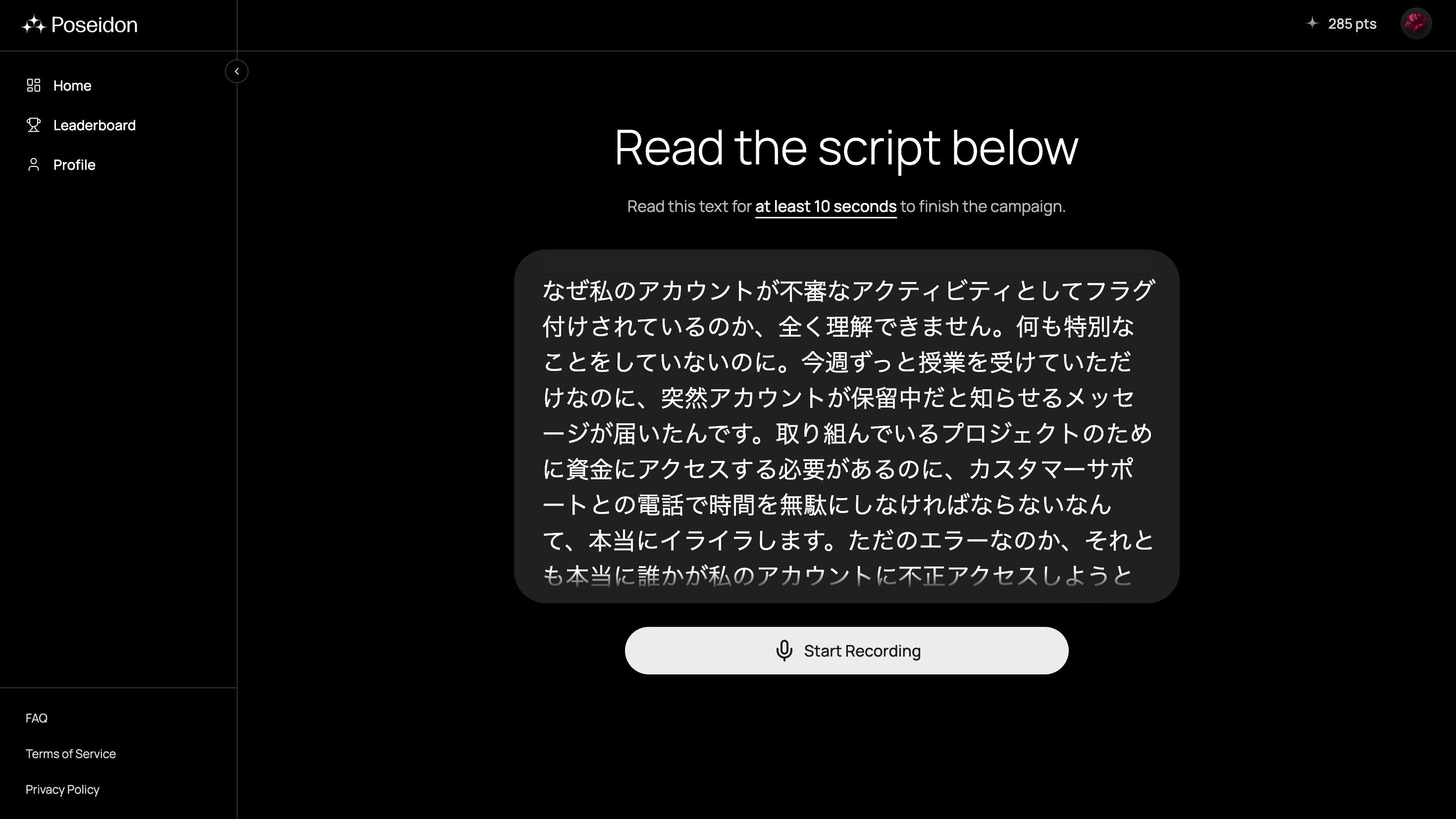
これを自分で聞き直して提出します。
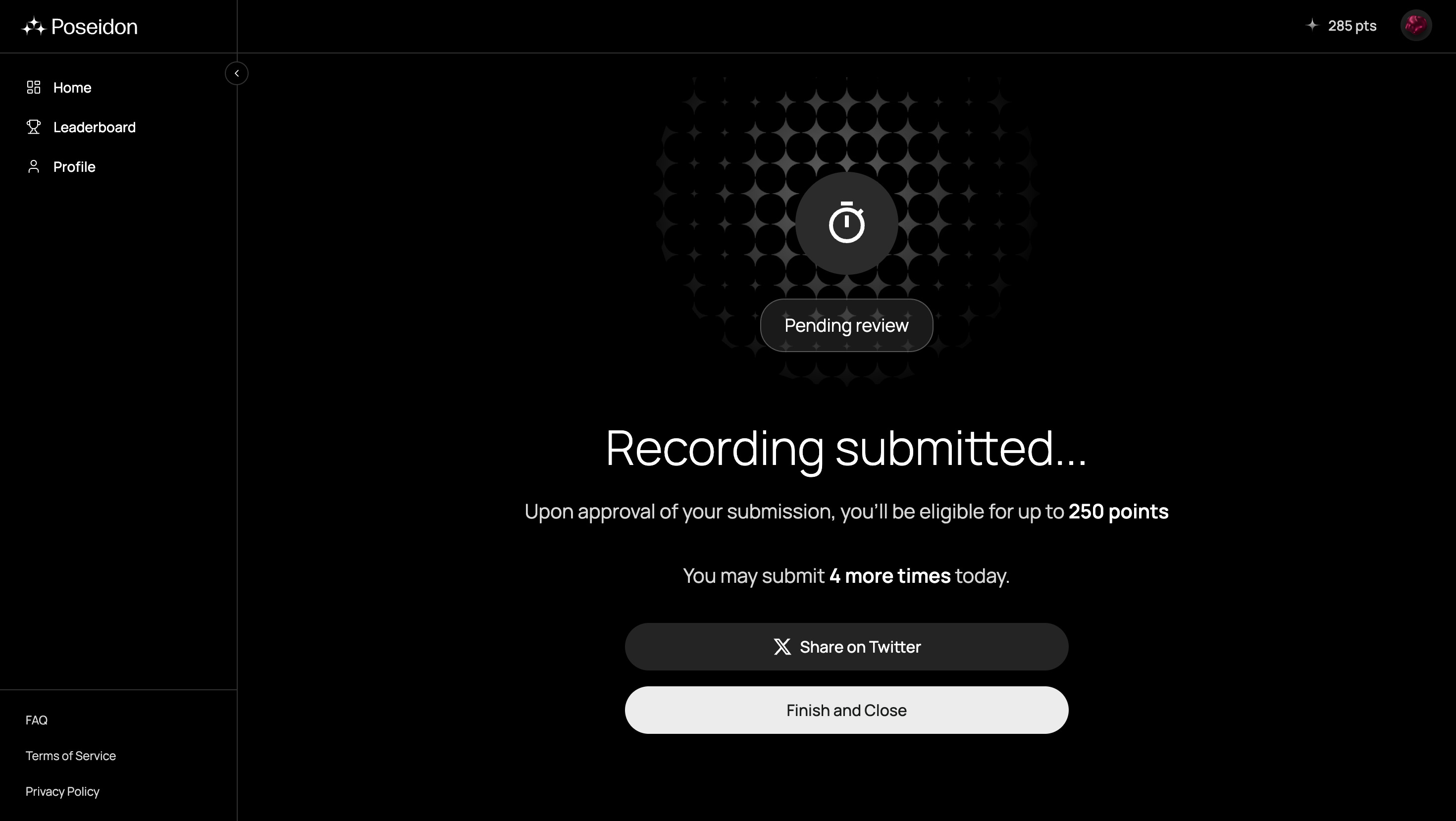
すると、少し時間が経つとレビューが完了し、報酬ポイントが振り込まれます。
現時点でトークンの情報や獲得したポイントがどのように扱われるのかは明言されていませんが、おそらく将来的にはトークンに変換されていくのではないかと考えられます。
後述しますが、このプロジェクトはStory FoundationのファウンダーがPoseidonのファウンダーを務めているなど、かなり力を入れているので、気軽に出来るDePINとして触ってみても良いかもしれません。
↓リファラルリンクです!よければぜひ!
https://app.psdn.ai/login?ref=FONWQRSG
(※この記事はStory Foundationの友人からリリース情報を教えて貰い、面白そうだったので書いています。金銭的な報酬は一切ありませんし、自らの意思で書いていますが、一応開示です。日本にも結構力入れたいらしいです。)
⚙️技術的な仕組み
Poseidonの基盤技術はStory Protocolのブロックチェーン上に構築されています
Story ProtocolはもともとIPの原本登録やライセンス管理のために設計された独自L1ブロックチェーンであり、Poseidonはこの上でデータを知的財産(IP)として登録・追跡することで、データ利用時の権利関係の明確化と大規模なコンプライアンス(法的順守)を実現しています。
データがStory上に登録されると即座に「親IP」となり、その後に人間のラベリングやAIによる生成で追加されたデータ(アノテーションや合成データなど)は「子IP」として紐づけられます。
これによりIPグラフと呼ばれる系譜構造が形成され、派生データがAIモデルの学習などに利用された際には、元の提供者からラベル付け者に至るまで自動的にロイヤリティ(利用料収入)が分配される仕組みです。
このロイヤリティ分配はスマートコントラクトによってオンチェーンで強制実行され、全ての関係者への帰属情報が改ざん不可能な形で保証されます。
また、データ自体もNFTのようなコンポーザブル(組み合わせ可能)なオンチェーン資産として扱われ、AIモデルが必要とする様々なデータセットを組み合わせたり再利用したりできる柔軟性を持たせています。
この辺りのStory Protocol自体の技術アーキテクチャは過去の記事でも触れているのでぜひご覧ください。

また、Poseidon固有の技術やデータ収集の方針についても解説します。
需要主導型(Demand-first): まずAI開発者側のニーズを特定し、それに見合ったデータ収集キャンペーンを立ち上げます。闇雲にデータを集めるのではなく、「どのようなデータが不足しているか」という需要に基づいて効率的に収集を行います。
分散型スケール: 世界中の個人や団体がデータ提供者(コントリビューター)として参加できるネットワークを構築し、多様で現実性の高いデータを大量収集します。スマートフォン向けのSDKや専用アプリなどのツールも提供されており、誰もが日常デバイスからデータ収集に参加できる仕組みになっています。
構造化された検証: 提供されたデータはPoseidonの自動キュレーションパイプラインによって整理・検品されます。例えば重複データの排除、フォーマットの標準化、メタデータの付与などを機械的に行い、不適切なデータや品質の低いデータはフラグで検出します。加えて、個人情報の除去や、AIでは判断が難しいケースについては人間のレビュワーが精査するなどhuman-in-the-loop(人間参加型)のプロセスで最終品質を担保します。
オンチェーンIPライセンス管理: Story Protocolのプログラム可能なIPライセンス層と不可変なIP登録台帳を統合し、データセットごとに明確な権利関係と利用許諾を付与します。これによりデータ利用時の著作権・ライセンス違反のリスクを低減し、OpenAIの音声モデル「Whisper」が直面したような著作権論争やデータ品質問題を回避できるアーキテクチャを実現しています。
Poseidonチームは「AIが現実世界で失敗しがちなケース(エッジケース)に狙いを定めて優先的にデータ収集し、各データセットはメタデータのチェックとStoryのIPライセンス機構による検証を経る」と説明しており、モデルに有用な難事例データを網羅しつつ法的なクリーンさも確保しています。
🚩変遷と展望
PoseidonはStory Protocol全体のChapter 2計画として位置付けられるAIデータ特化の新規プロジェクトであり、Story Protocol自体が主導して立ち上げ、出資もする形で技術的・コミュニティ的支援を行っています。
開発チームはStory Protocolの共同創業者でCEOでもあるSeung Yoon “S.Y.” Lee氏がPoseidonのプレジデント(代表)を務め、AI研究者のSandeep Chinchali氏とエンジニアのSarick Shah氏が共同創業者として参画する形で発足しました。

S.Y. Lee氏は韓国のカカオエンターテインメントでグローバル戦略責任者を務め、過去には自身の創業した小説プラットフォーム企業を440百万ドルで売却した経験も持つ連続起業家であり、Poseidonでは事業戦略とエコシステム拡大を指揮しています。
Sandeep Chinchali氏はスタンフォード大学で博士号を取得したAI・ロボティクス研究者で、テキサス大学オースティン校の助教授としてエッジコンピューティングやネットワークロボットに関する研究室を率いています。
加えて、Story Protocolのもう一人の共同創業者であるJason Zhao氏も重要な関係者です。Zhao氏は2025年8月にStory ProtocolのCEO職から戦略アドバイザーに退く形でPoseidonに注力することを表明しました。DeepMindでの研究経験も持つ彼は、「言語生成AIは序章に過ぎず、今後あらゆる分野に知能が浸透する新たな産業革命が起こる」と述べており、Poseidonを通じて科学、バイオ医薬、宇宙開発といったフロンティア領域へAIを応用していくことに情熱を傾けています。
そんなPoseidonは2025年7月に1,500万ドルのシード資金調達を実施しており、Story Protocolへも巨額出資をしているa16zの暗号資産部門がリード投資家を務めました。
また、Poseidonはサービス開始当初から実利用に向けたパートナー企業との協業を進めています。その一例として、名前は非公開ながら大手ロボティクス企業がPoseidonのネットワークから自社AI向けのデータ供給を受け始めており、また音声AIの基盤モデルを開発するチームが各国の方言を網羅した音声データをPoseidon経由で調達していることが明らかにされています。
さらに複数の大学研究機関やフォーチュン500企業(大手グローバル企業)も、AI開発力強化のためPoseidonへの参加やデータ提供に関心を示しているとのことです。
現在は上述した通り、音声データの収集アプリからスタートしており、今後はその拡大や収集データの拡大に加えて、データ提供者向けモジュールやSDK、ライセンス統合ツールの開発を進めており、2025年夏の終わりまでに早期アクセス版をリリースして外部開発者やパートナー企業が試用できるようにする計画とのことです。
💬RoboFi市場のフラッグシップアプリ
最後は総括と考察です。
とても面白いアプリですね。AIの発展における課題感はかなり叫ばれていることで、特に音声収集は個人情報に紐づくデータなので既存のWeb2企業が勝手に学習することがかなり困難です。
利用規約を更新すればできるかと思いますが、ユーザーは変更された規約に対して嫌悪感を示すことが容易に想像できます。
それらに対してブロックチェーンを活用しDePIN的にデータ収集をすることは非常に理にかなっています。まずデータ提供に対して報酬を配分できるのでユーザーの納得感があり、企業側も高価なマーケティング費用をかけることなくデータ収集ができます。また、それらのデータをブロックチェーン上に刻み管理することで、データ学習に利用された際にロイヤリティーフィーを支払うことができます。
で、こういった話は以前から言われていましたが、意外に直近で一番マッチする市場がこの音声収集市場なのではないかと思っています。
実は自分自身も対話AIのアップデートのために音声収集をしたことがあり、そのための規約の作成、音声を提供してくれる人の募集、同意書に書いてもらう、などなどをしたことがあるので、その大変さがわかります。
だからこそ、Poseidonのソリューションは非常に魅力的に思います。
今後どのように発展していくのかはわかりませんが、音声収集やRoboFi市場はかなり伸びていくと思いますし、その中でPoseidonはフラッグシップ的なアプリになっていくのではないかと思うので、自分でももう少し触ってみて、何か大きな続報があればまた記事にします!
↓リファラルリンクです!よければぜひ!
https://app.psdn.ai/login?ref=FONWQRSG
以上、「Poseidon」のリサーチでした!
🔗参考リンク:HP / APP / X
«関連 / おすすめリサーチ»



免責事項:リサーチした情報を精査して書いていますが、個人運営&ソースが英語の部分も多いので、意訳したり、一部誤った情報がある場合があります。ご了承ください。また、記事中にDapps、NFT、トークンを紹介することがありますが、勧誘目的は一切ありません。全て自己責任で購入、ご利用ください。
✨有料購読特典
月額10ドル(年額80ドル/月額6.6ドル)で有料購読プランを用意しています。有料購読いただいている方には以下の特典がございます。
週2本の限定記事の閲覧
月曜:1週間のマーケット&ニュースまとめ記事(国内外の20以上メディアから1週間のニュースをキュレーションして紹介)
木曜:Deep Report記事(通常の内容よりも深い調査や考察を盛り込んだ記事 / 公開記事では言えない裏事情も偶に公開)
1,500本以上の過去記事の閲覧
無料で公開された記事も公開1週間後以降は有料購読者以外は閲覧できなくなります。すでに1,500本以上の過去記事が存在し、その全てを見放題です。
不定期のオフ会への参加
オフライン/オンラインにて不定期で有料購読者限定のオフ会を開催します。
※特典は現時点のものであり今後変更の可能性がございます。変更の際はニュースレターでお知らせします。
About us:「web3 for everyone」をコンセプトに、web3の注目トレンドやプロジェクトの解説、最新ニュース紹介などのリサーチ記事を毎日配信しています。
Author:mitsui @web3リサーチャー
「web3 Research」を運営し、web3リサーチャーとして活動。
Contact:法人向けのリサーチコンテンツの納品や共同制作、リサーチ力を武器にしたweb3コンサルティングや勉強会なども受付中です。詳しくは以下の窓口よりお気軽にお問い合わせください。(📩 X / HP)
→お問い合わせ先はこちら